Dbt (or data build tool) transforms the way you work with sql, if you are someone like me that comes from a software engineering background then you will feel at home with the dbt workflow. So let’s get to it, first what is dbt?
Dbt is an open-source command line tool that helps analysts and engineers transform data in their warehouse more effectively.
Ok this is what dbt is according to wikipedia, but lets try to get a little better understanding then that. When I’m working with dbt it reminds me of working with a compiler, i write my dbt code, compile it into sql code and then i can execute my query or tests right from the terminal using the dbt cli. But don’t think that is all that dbt does, while the compiler is part of the core of what is dbt it’s much more then just that. I also mentioned that I can run my compiled sql code in the terminal using dbt, this is another core part of what makes up dbt. by letting dbt compile and then run code it allows it to understand the dependencies between the different models and do powerful things like run the models in order of their dependencies. These are some of the things that i will mention in this article.
Dbt code
First lets talk about dbt code and what it is. Dbt code is simply put sql code combined with jinja and some extra features sprinkled on top of that.
Using jinja together with sql will enable you to write things like loops and
if statements which can be great tools when creating models.
However it is those extra features which really let dbt shine.
Probably the most important of these features is the ref() function.
The ref() function reference other models in the dbt project
and it lets you reference those model using only the model name (same as
file name) without having to specify the database or schema.
select
*
from {{ref('model_name'}}
Instead dbt let’s you specify the database and schema in a config file. This makes it easy to change database and schema depending on if you are in a development environment or production environment.
By letting dbt handle the references between different models it allows dbt to build a dependency graph during compilation of the dbt models. Using this dependency graph dbt can then run all the models in order of their dependencies.
Another important function in dbt is the source() function.
This function works similar to the ref() function except that it references
a source table instead of another dbt model and just like the ref() function
a .yaml config file define the sources.
select
*
from {{source('source_name', 'table_name')}}
Profiles
Before we start talking about the dbt cli i have to mention profiles which is only needed when using dbt cli and not if you are using dbt cloud (which I will not discuss in this article because honestly I have no experience using it).
Dbt uses profiles and targets to know which data warehouse to connect to.
Inside the file profiles.yml are the profiles and target defined and this
file can either be inside the project directory or inside the ~/.dbt/
directory.
The beauty with this is that you can reuse the same profile and
profiles.yml file for projects that uses that same warehouses and you can
use different targets depending on your environment.
A typical workflow includes having at least one dev environment target and a
prod environment target.
profile_name: # a profile
target: target_name # defines the default target
outputs:
target_name: # a target
type: <bigquery | postgres | redshift | snowflake | other>
schema: schema_name
database: database_name
account: account_name
role: role_name
user: user_name
password: very_secure_password
threads: 4
warehouse: warehouse_name
### database-specific connection details
...
second_target_name: # a second target
...
second_profile_name: # a second profile
...
Materialization strategies
Another great feature in dbt is that is supports four different materialization
strategies. Materialization strategies tells dbt how it should handle
persisting dbt models in your warehouses. Basically it tells dbt how it will
build a model and what to do if the model already exists.
The four strategies that dbt supports are table, view, incremental and
ephemeral.
Table
This materialization strategy makes dbt build a table, overriding any
existing table with the same name. A table is good because it is fast to
query from, so any model that gets querried often, used by
downstream models or if query latency is important.
However it’s important to remember that a table don’t always
represents the latest data from it’s source because the source may have
updated after the table got built.
View
In many ways a view is an opposite to a table, but let’s start with what
they have in common. Like a table a view is rebuilt entirely every time it
run, it has no “memory” of previous runs. However how the view is different
in that it don’t store data in any storage, whenever it’s querried it
will build the view. This let’s it always reflect the latest data from it’s
source by the cost of speed. Stacking views on top of each other can
take a long time to run so be careful with using view too often.
Incremental
Using the incremental materialization strategy will result in the model
creating a table just like the table materialization strategy, however
unlike table the incremental materialization strategy will not overwrite
any existing table created by a model. It will instead either update
existing rows or append new rows to the existing table.
Because you are updating or appending to an existing table you don’t have to transform old data that the model has already transformed. This can greatly increase the speed of your models because you don’t have to process the same data more then once.
However to be able to update rows in a table dbt needs to know which rows
should update and which rows should append to the table.
To do this we need to give each row a unique_key which can consist of
one or more columns. How to pick the unique_key depends on the data but
it’s important that no column that is part of the unique_key has
any null values.
For example lets say we have a fruit store and at the end of every day we
want to update a table with information about how much fruit we have sold.
Let’s say we have the columns date, fruit_name and amount_sold.
In this case it makes sense to set the unique_key to be a combination of
date and fruit_name, because we know for each day each fruit_name will
be unique and each date will be unique because that is how dates work.
| date | fruit_name | amount_sold |
|---|---|---|
| 2023-01-10 | Apple | 10 |
| 2023-01-10 | Banana | 12 |
| 2023-01-10 | Orange | 8 |
| 2023-01-09 | Apple | 9 |
| 2023-01-09 | Banana | 10 |
| 2023-01-09 | Orange | 9 |
Ephemeral
The ephemeral materialization strategy is a bit different from the previous
strategies (to be honest I have not used this one myself).
When using this materialization strategy no tables are actually built in the
warehouse, in this way it’s similar to a view however it’s still possible to
select from a view while it’s not possible to select from the ephemeral
model. Instead other dbt models that depends on the ephemeral model will use
dbt to interpolate the ephemeral model as a common table expression in the
dependent model.
Using the ephemeral materialization strategy can be a great way to reduce
clutter in your repository but be careful to not to overuse this strategy as it
can make it difficult to debug your code.
Dbt cli
Now you should have some understanding of the benefits of using dbt and
how you can write dbt code.
Now I want to talk how to use dbt from the terminal to do things like
compiling, testing and running your dbt code. I mentioned earlier that
functions like ref() is crusial to get the most out of dbt but if you don’t
use dbt cloud then the dbt cli is also crusial.
DBT compile
DBT compile is a dbt cli function that will compile your dbt code and output
the compiled code (pure sql code) to the target/ directory.
This makes it much easier to debug the models, especially if you use a lot of
jinja code or macros. It can also save you time while developing models
because it gives you a quick feedback loop for any compile errors that may
be in your dbt code. Because the compiling happens on your local machine
you don’t have to wait for the code to upload to wherever you run your
models.
The following is an example of the dbt code and how it looks after compilation.
SELECT
*
FROM {{ref('model_name'}}
SELECT
*
FROM database_name.schema_name.model_name
Another benefit of inspecting the compiled dbt code is that it allows you
to copy the compiled code and execute it directly. This is useful
when debugging your models as it allows for a faster feedback loop.
This is also the stage where dbt will generate the dependency graph
(as long as you are using the ref() function which will allow dbt to run
your models in order of their dependencies).
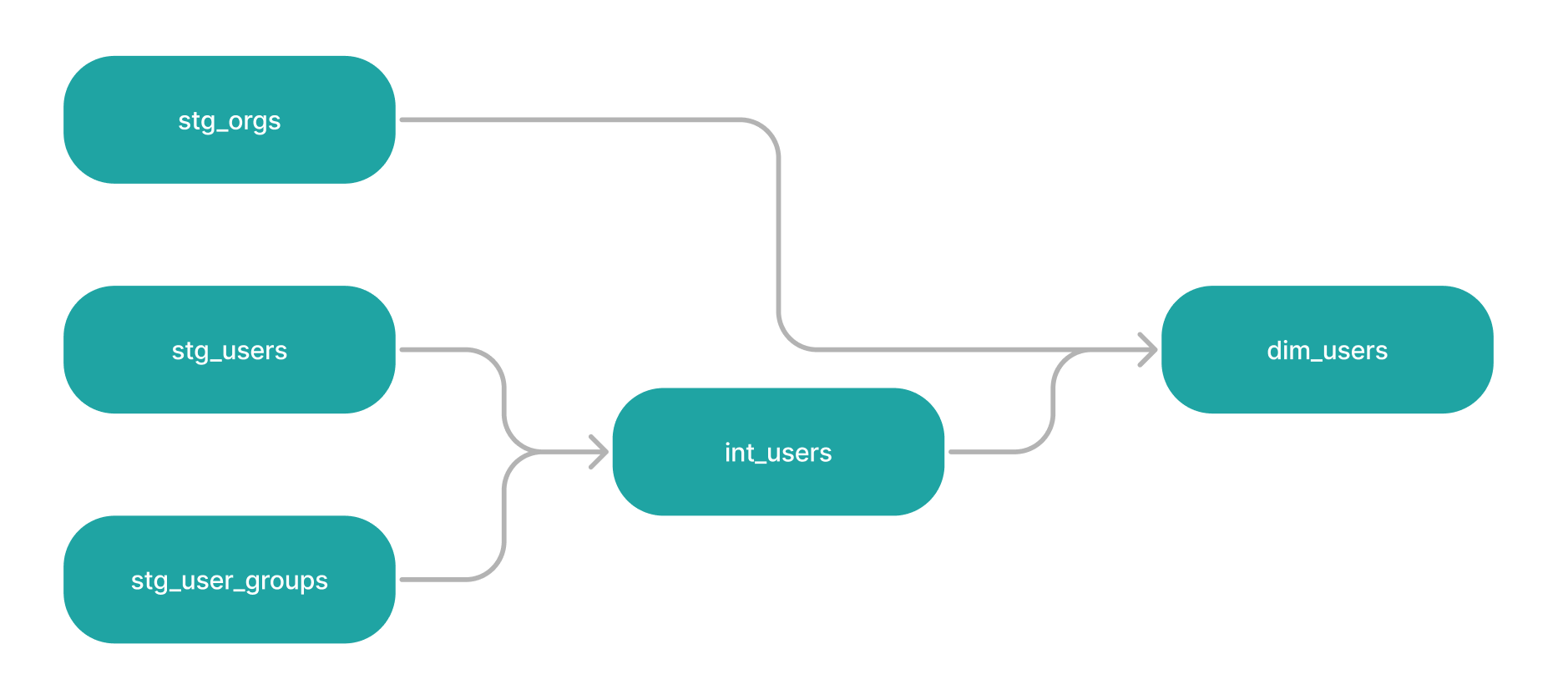
Figure 1: example DAG, source https://docs.getdbt.com/terms/elt
DBT run
Once you have your compiled dbt code it’s time to run it and that is what
the command dbt run does. However it is important to note that you do not
need to run the dbt compile before running dbt run. dbt run will make
sure that the models that you run compile, which includes not just
compiling the dbt code but also building the dependency graph which
determines the order that dbt run will run the models.
Running dbt run without any arguments will tell dbt to run all your models
in dependency order, however it’s possible to tell dbt to only run specific
models. This is done by providing the --select flag along
to dbt run. This flag also needs an argument to specify which model(s)
to select. The following examples show different ways to use the
--select flag.
dbt run --select my_dbt_project_name # runs all models in your project
dbt run --select my_dbt_model # runs a specific model
dbt run --select path.to.my.models # runs all models in a specific directory
dbt run --select my_package.some_model # run a specific model in a specific package
dbt run --select tag:nightly # run models with the "nightly" tag
dbt run --select path/to/models # run models contained in path/to/models
dbt run --select path/to/my_model.sql # run a specific model by its path
Finally there is one more flag that I want to mention and that is the
--full-refresh flag. As discussed earlier dbt supports
different materialization strategies. Imagine you are using the incremental
materialization strategy but while developing maybe you want to
rebuild the entire table instead of updating or appending the table.
You could manually delete the table and then use dbt run to re-create the
table. This works fine but dbt offers a better solution, when using the
--full-refresh flag you tell dbt that it should first delete the table
before building a new table, even if you are using the incremental
materialization strategy.
DBT test
In the beginning I mentioned that you can use dbt cli to run your model
tests and while I have not mentioned how testing works with dbt I will
now talk about how to run your tests.
I will talk more about specific dbt tests further down in this article,
here I will just talk about how to run your tests from using dbt cli.
Once you have defined your tests for your dbt models you can run the tests
using their command dbt test. This works similar to how the dbt run
command works, just running the dbt test command with no flags will make dbt
run every test in your project. However just as the dbt run command
you can add the --select flag to specify which tests that you want to run.
The following examples show how to run dbt test with different flags.
dbt test --select one_specific_model # run tests for one_specific_model
dbt test --select some_package.* # run tests for all models in package
dbt test --select test_type:singular # run only tests defined singularly
dbt test --select test_type:generic # run only tests defined generically
dbt test --select one_specific_model,test_type:singular # run singular tests limited to one_specific_model
dbt test --select one_specific_model,test_type:generic # run generic tests limited to one_specific_model
DBT build
The last command I want to mention is the dbt build command. This command
don’t really do anything new that any previous command does.
However what it does is to combine the functionality of the commands
dbt compile, dbt run and dbt test. Meaning that when using the
dbt build command you tell dbt to compile the code, run the models
and run the tests.
It also supports the same flags as some previous commands, the most important
flags is the --select and -full-refresh flags that I have
mentioned earlier.
Tests
Now it’s finally time to discuss how to actually create tests in dbt.
Dbt supports two different kinds of tests, singular tests and generic tests.
Singular tests are tests that created for a specific model,
This allows you to custom tailor the test for a specific model letting
you test specific logic for that model.
To reference which model to test you use the ref() function that I have
mentioned earlier. The following is an example of a singular test.
-- Refunds have a negative amount, so the total amount should always be >= 0.
-- Therefore return records where this isn't true to make the test fail
select
order_id,
sum(amount) as total_amount
from {{ ref('fct_payments' )}}
group by 1
having not(total_amount >= 0)
The other kind of tests that dbt supports are the generic tests and these
tests can be a little more interesting because these are tests that can
run on any model.
Because these tests can run on any model in your project they need to be
generic (as the name implies). An example for a generic test can be to make
sure that a column contains no null values. To run a test like this
you need two parameters, the model name and column name to run the test on.
But once the test is created it can be used for any number of models
and columns. Here is an example of a generic test.
{% test not_null(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} is null
{% endtest %}
Some of these generic tests are common when testing your models, because of this dbt ships with some generic test already built in to dbt. These are tests that you will probably use on all of your dbt models together with your singular tests for your models. The following is descriptions of these different out of the box tests.
Out of the box tests
unique
The first out of the box test in dbt that I will talk about is unique
which ensures that there are no duplicate rows in the dataset.
This test take column names as a input and makes sure that each row has an
unique combination of the given columns.
This test is important if you are using the incremental materialization
strategy since it requires each row to have a unique key combination.
Let’s say you have a model that runs every day, it reads from sources and calculates how much each customer has spent for the given day. In this example you probably want a unique identifier for the customer together with the data to be a unique combination. Because each row tells how much a customer has spend we don’t want two rows with the same customer on the same day.
not_null
Another test we will talk about is the not_null test.
This test will check if the specified columns contains any null values.
If you have any columns that should never be null, just add this test.
Just like the unique test this test works well together with the
incremental materialization strategy because each column in the
unique key has to have a value that is not null.
This tests works well together with the unique test, lets think
back to the previous example that tests to make sure that each customer
only appears once every day. Imagine if the date or the customer identifier
is null, then the unique test will eventually start failing once there
are rows with these null values. So adding the not_null tests
for the column you use to get the unique combinations is highly recommended.
accepted_values
The test acceptable_values is similar to the not_null test. It takes a
column name and an array of the acceptable values and makes sure that the
all rows inside the specified column has acceptable values.
An example would be if you have a model that calculates how fast the car
has driven for a given day. In this case you probably want to make sure
that no car is moving faster then 299,792,458 m/s (the speed of light)
or that it’s moving in a negative speed.
relationships
The final out of the box test I will discuss is relationships.
This test validate the relationships between different models.
So let’s again go back to our customer example, when reading from the
customer identifiers from source tables we can use the relationships
test to make sure that each customer id in the source table exists in the model.
This way you can make sure that your model don’t miss any customers.
Documentation
The last thing that I want to mention is how dbt can help you generate a static documentation site for your models. Dbt automatically generates information about your models such as a DAG showing your model dependencies, columns, column types, table size and more. But besides the information automatically generated by dbt you can add your own descriptions to both columns and tables. This can greatly help the consumers if these models to understand them better.
To generate this documentation just run the command dbt docs generate,
but make sure that you use dbt run before generating the documentation
to be sure you get all the information about your models.
Dbt also comes with the command dbt docs serve to help you try out your
documentation locally. However it’s recommended to deploy the documentation
using a CI/CD pipeline, so the documentation always gets updated when new
changes gets pushed to production.
To deploy our documentation at Tele2 we uses CI/CD to deploy our model
documentation to GitLab pages.
Figure 2: example documentation, source https://docs.getdbt.com/terms/elt
Conclusion
There are a lot of features that I have barely mentioned and some that I have not mentioned at all, but this article is getting longer and longer and I feel I could keep writing forever. Hopefully you now have some understanding of what dbt is and how you can use it in your projects. DBT comes with plenty of great features that once you use them you will not want to go back to not using them. I will end with a short summary of my favorite features in dbt that I have mentioned in this article.
- The workflow reminds me more of traditional software development using the cli.
- I can configure profiles to setup connections to my warehouses across multiple projects.
- Using the
ref()andsource()functions makes it easy to reference other tables inside and outside your dbt projects. - Easy to setup different materialization strategies for your models.
- Comes with some handy out of the box tests, especially if you are the incremental materialization strategy.